
How to be proud of an experimentation
Sometime, even if it’s not that easy, trying hard to resolve something you are not sure about, at the end you can be proud about what you’ve done and God it’s good to feel proud about something you achieved.
The context
With one of my colleague, we were working on a solution that would ensure a proper graceful shutdown for a NodeJS application.
Below is a minimized C4 model.
The problem :
- Asynchronous services to process thousands of data that gives business insight for our clients (message loss tolerance is 0)
- A parent process forking a child process to instantiate a queue consumer
- A queue consumer instance which is not available from the parent process
- A
SIGTERMsent on a node child process will instantly kill the child- Any consumer running at this time would be instantly killed resulting in:
- queue consumed messages loss
- missing to be processed data for our client
- Any consumer running at this time would be instantly killed resulting in:
- A local environment not ready to test this kind of scenario
- The feedback loop was around 24 to 36 minutes (too long!) with at least all these steps:
- commit / push
- CI running:
- execute test (5 minutes)
- dockerize (5 minutes)
- publish docker image (2 minutes)
- deploy docker container (2 minutes)
- create a new test instance (2 minutes)
- clean data (2 minutes)
- launch test (4-15 minutes)
- observe result (2-3 minute)
Below is an example of our activity:


As you can see there is a pattern with a long time interval between commit/push and test session (let’s say around 6 to 8 tests a day).
BTW, thanks to @Arnaud Bailly and his wonderful sensei project
Entering the solution space
Our work in progress :
Understand the current behaviour which can be resumed to:
What we intend to do, listen to a SIGTERM signal from the main node process, and properly shutdown the service by propagating the information
to the forked child. Which can be resumed to:
Still, we are slowed down by the all process and feedback loop. Let’s take a step back for a moment and see if we don’t have a solution to reduce our feedback loop.
How to reduce feedback loop?
- By removing the actions that take time
- By decreasing the number of actions
In our context it was obvious we should target our local development environment instead of going on a staging environment.
… we don’t have a maintained local environment 😱, no problem, let’s experiment and identify what is needed to have a local environment.
Identify a local strategy test
How to prove that our workaround is working?
- Run the app on a docker container
- Run a redis service on a docker container
- Send a few thousand requests on the resource exposed to handle events
- Check that redis queues are created and populated
- Store the events in a database
- Expose the database file on a docker volume (we need to have a persistent db file that is updated after each restart)
- Run a
docker stop CONTAINERcommand - Check that the numbers add up between the events stored in database end the events left in the queue
- Restart the docker container
- Check the redis queue is consumed
- Re-run from step 7
Implement sqlite repository
Prerequisites : npm install sqlite sqlite3
Purpose :
- Persist our events on a local database
- No dependency with a distant service to persist data during test sessions on a local environment
- Easily inspect results during test sessions
Fortunately we did some weeks ago a refactoring work to add some abstraction and separation of concerns regarding our persistence layer.
Basically, we use the Repository pattern (See Eric Evans DDD blue book).
Thanks to this pattern and the previous work, what we needed is:
export interface Repository<T> {
persist(entity: T): Promise<void>
}
abstract class AbstractSQLiteEntitiesRepository<T> implements Repository<T> {
async persist(entities: T): Promise<void> {
return Promise.resolve({
/*
persist the entities
*/
})
}
}
export type EventsRepository = Repository<Events>
export class SQLiteEventsRepository
extends AbstractSQLiteEntitiesRepository<Events>
implements EventsRepository
{
query(entities: Events): Promise<void> {
return Promise.resolve(
/*
run the query
*/
)
}
}
// And then we replace the actual repository injection
await handleEvents({
events: SQLiteEventsRepository, // SQLiteEventsRepository instead of DistantEventsRepository
})
Configure docker
docker-compose volumes to persist sqlite data :
agent:
build:
context: ..
dockerfile: deployments/app/Dockerfile
args:
NODE_VERSION: ${NODE_VERSION}
NPM_VERSION: ${NPM_VERSION}
PORT: ${PORT}
target: local-agent
volumes:
- "./volumes/db/data:/usr/db/data"
restart: unless-stopped
docker-compose expose agent network :
agent:
build:
context: ..
dockerfile: deployments/app/Dockerfile
args:
NODE_VERSION: ${NODE_VERSION}
NPM_VERSION: ${NPM_VERSION}
PORT: ${PORT}
target: local-agent
+ ports:
+ - 3001:3000
+ network_mode: bridge
volumes:
- "./volumes/db/data:/usr/db/data"
restart: unless-stopped
docker-compose configure redis :
version: '3.4'
services:
redis:
image: redis:6.2.7-alpine
container_name: redis
healthcheck:
test: redis-cli -p 6379 ping > /dev/null && echo OK
retries: 3
timeout: 3s
ports:
- "6379:6379"
volumes:
- "./volumes/redis/data:/data"
network_mode: bridge
restart: unless-stopped
docker-compose configure main app :
app:
build:
context: ..
dockerfile: deployments/app/Dockerfile
args:
NODE_VERSION: ${NODE_VERSION}
NPM_VERSION: ${NPM_VERSION}
PORT: ${PORT}
target: app
ports:
- "${PORT}:${PORT}"
healthcheck:
test: curl -f -s -o /dev/null http://localhost:${PORT}/health && echo OK
retries: 3
timeout: 3s
links:
- redis
labels:
- traefik.enable=true
- traefik.http.routers.connector.rule=Host(`host.${BASE_DOMAIN:-localdomain}`)
- traefik.http.routers.connector.entrypoints=websecure
- traefik.http.routers.connector.tls.certresolver=myresolver
network_mode: bridge
restart: unless-stopped
docker-compose configure env variable :
agent:
build:
context: ..
dockerfile: deployments/app/Dockerfile
args:
NODE_VERSION: ${NODE_VERSION}
NPM_VERSION: ${NPM_VERSION}
PORT: ${PORT}
target: local-agent
links:
- redis
+ environment:
+ - NODE_ENV
+ - LOG_LEVEL
+ - SQLITE_FILEPATH
+ - QUEUE_TYPE
+ - QUEUE_CONSUMER_TYPE
+ - QUEUE_BATCH_SIZE
+ - QUEUE_AGENT_WORKER_TTL
+ - QUEUE_BATCH_TIMEOUT
+ - QUEUE_POLL_FREQ
+ - REDIS_HOST=redis
+ - REDIS_PORT=6379
ports:
- 3001:3000
network_mode: bridge
volumes:
- "./volumes/db/data:/usr/db/data"
restart: unless-stopped
app:
build:
context: ..
dockerfile: deployments/app/Dockerfile
args:
NODE_VERSION: ${NODE_VERSION}
NPM_VERSION: ${NPM_VERSION}
PORT: ${PORT}
target: app
ports:
- "${PORT}:${PORT}"
healthcheck:
test: curl -f -s -o /dev/null http://localhost:${PORT}/health && echo OK
retries: 3
timeout: 3s
links:
- redis
+ environment:
+ - NODE_ENV
+ - LOG_LEVEL
+ - PORT
+ - REDIS_HOST=redis
+ - REDIS_PORT=6379
labels:
- traefik.enable=true
- traefik.http.routers.connector.rule=Host(`host.${BASE_DOMAIN:-localdomain}`)
- traefik.http.routers.connector.entrypoints=websecure
- traefik.http.routers.connector.tls.certresolver=myresolver
network_mode: bridge
restart: unless-stopped
So, after some hours of work, we had our local environment ready to test 🙌!
… Almost. We had to troubleshoot the solution until it worked, but mainly we were doing:
- Run the container, fix until ✅
- POST event requests on the resource
- Check the queue was filled, fix until ✅
- Check the queue was consumed, fix until ✅
- Check that the event was persisted, fix until ✅
OK, we are ready to launch test sessions, observe the system and code what is missing.
Local testing
I will not hold the suspense and share the improvement done with our feedback loop:
- Build the docker images (3 minutes)
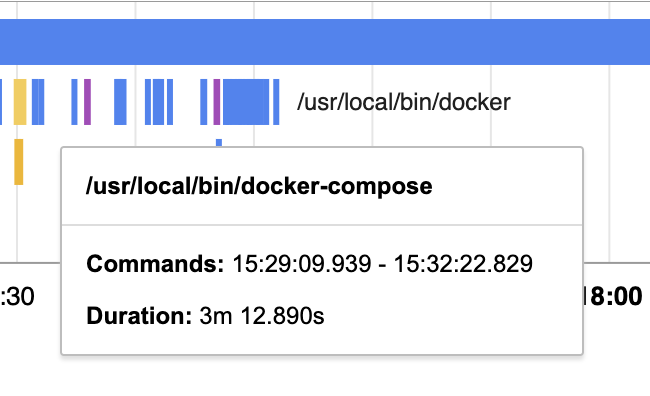
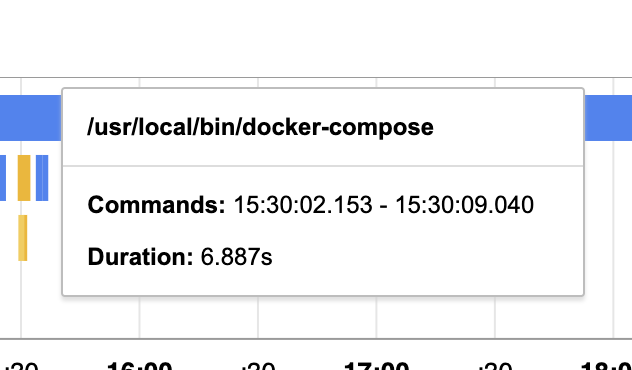
- Run the docker containers (6 seconds)
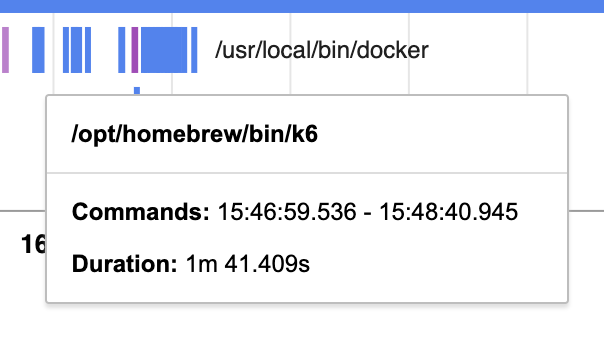
- Run K6 to perform POST requests (1.4 minutes)
- Observe results:
- Check redis queues
- Check events are persisted
- Stop docker agent container
- Check app logs
[ {"level":"INFO","time":1664442175682,"command":"stop-node-process","payload":{"message":"SIGTERM received on pid 1"}}, {"level":"INFO","time":1664442175683,"command":"stopped-node-process","payload":{"message":"Node process stopped gracefully"}}, {"level":"INFO","time":1664442175684,"command":"stop-node-process","payload":{"message":"message received on pid 18"}}, {"level":"INFO","time":1664442175683,"command":"stopped-node-process","payload":{"message":"Node process stopped gracefully"}} ] - Check lock registry has been flushed
127.0.0.1:6379> GET workerRegistry:events "29"
What is important here is:
- Number of steps before observing results have been reduced, from 7 to 3
- Time spend to build and run has been reduced, from 24 minutes (at best) to a bit less than 5 minutes
- Our implementation is not working as expected, we still have a lock in our registry targeting a child process that has not been stopped (and doing the sum up between what we have in database and what we have left in the queue confirmed it)
But that is not a problem anymore as we can deploy in less than 5 minutes.
Let’s take a look at what we’ve missed. We now know that the parent process has been forked after the SIGTERM has been
received, that means we have a kind of state machine to implement:
- Do not fork the parent process if a
SIGTERMhas been received
Implement it, test it!
Doing the exact same process explained above we finally came to a solution and our test session result is:
- First Stop
- 43572 events in redis queue at start
- 42672 events in redis queue when docker stops
- Lock registry cleaned
- 900 events present in database (numbers add up ✅)
- Second Stop
- 42672 events in redis queue
- 42222 events in redis queue when docker stops
- Lock registry cleaned
- 1350 events present in database
- 1350 - 900 = 450 (Youhou, all is good)
- Third Stop
- 42222 events in redis queue
- 36972 events in redis queue when docker stops
- 6600 events present in database
- 6600 - 1350 = 5250 (number add up ✅)
- Fourth Stop
- 36972 events in redis queue
- 25897 events in redis queue when docker stops
- 17675 events present in database
- 17675 - 6600 = 11075 (number add up ✅)
Conclusion
It took us 2 days, 2 days and half to rework our local environment.
At the end we succeeded to
- reduce the feedback loop by 5
- reduce the number of steps by 2
- implement a solution
Having the smallest possible feedback loop when building a software is a target to reach and think about all the time.
This is one of the pillar in continuous improvement.
Where is the pride in all of that?
Of course, we are proud to have succeeded but there is more than this. We took the time to experiment, to switch uncertainty to certainty. We improved the product to first ease our colleagues work and second to be more efficient for our users in the future, because what you do as a software developer is not only for yourself, it is for all the people involved one day or another in the product you’ve been working on.
Thanks
- To Stéfanie who took the time to read it and gave me feedbacks (the conclusion about the pride is on her 🙏)
- To Marc who gave me some tricks about the look and feel
The code
The agent
class Agent {
protected timer?: NodeJS.Timer
private killSignalReceived = false
constructor(
protected config: AppConfig,
protected log: Logger,
protected redisService: RedisClientService,
) {
}
async checkQueue(param1: string, param2: string): Promise<void> {
//...
if (!this.killSignalReceived) {
const child = fork(agentFilePath, [param1, param2])
Process.sigterm(log).register(
async () => {
this.killSignalReceived = true
await Promise.resolve(void child.send('graceful-stop'))
},
() => void Promise.resolve(),
)
await QueueConsumer.registerLock(redisService, param1, param2, child.pid)
}
}
}
The Process class
interface Processor {
register(func: () => Promise<void>, cleanup: () => void): void
}
export class Process {
static sigterm = (log: Loggerable): Processor => {
return Process.on('SIGTERM', log)
}
static exit(): void {
process.exit(0)
}
static on(event: string, log: Loggerable): Processor {
return {
register(func: () => Promise<void>, cleanup: () => void): void {
process.on(event, () => {
log.info({
command: 'stop-node-process',
payload: { message: `${event} received on pid ${process.pid}` },
})
func()
.then(() => {
log.info({
command: 'stopped-node-process',
payload: { message: 'Node process starting cleanup' },
})
cleanup()
})
.catch((err) => {
log.error({
command: 'stop-node-process',
payload: { err: JSON.stringify(err), event },
})
process.exit(1)
})
})
},
} as Processor
}
}